After a long hiatus, I’d like to renew the discussion of axiomatic categorical set theory, more specifically the Elementary Theory of the Category of Sets (ETCS). Last time I blogged about this, I made some initial forays into “internalizing logic” in ETCS, and described in broad brushstrokes how to use that internal logic to derive a certain amount of the structure one associates with a category of sets. Today I’d like to begin applying some of the results obtained there to the problem of constructing colimits in a category satisfying the ETCS axioms (an ETCS category, for short).
(If you’re just joining us now, and you already know some of the jargon, an ETCS category is a well-pointed topos that satisfies the axiom of choice and with a natural numbers object. We are trying to build up some of the elementary theory of such categories from scratch, with a view toward foundations of mathematics.)
But let’s see — where were we? Since it’s been a while, I was tempted to review the philosophy behind this undertaking (why one would go to all the trouble of setting up a categories-based alternative to ZFC, when time-tested ZFC is able to express virtually all of present-day mathematics on the basis of a reasonably short list of axioms?). But in the interest of time and space, I’ll confine myself to a few remarks.
As we said, a chief difference between ZFC and ETCS resides in how ETCS treats the issue of membership. In ZFC, membership is a global binary relation: we can take any two “sets” 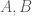 and ask whether
and ask whether 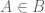 . Whereas in ETCS, membership is a relation between entities of different sorts: we have “sets” on one side and “elements” on another, and the two are not mixed (e.g., elements are not themselves considered sets).
. Whereas in ETCS, membership is a relation between entities of different sorts: we have “sets” on one side and “elements” on another, and the two are not mixed (e.g., elements are not themselves considered sets).
Further, and far more radical: in ETCS the membership relation 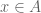 is a function, that is, an element
is a function, that is, an element  “belongs” to only one set
“belongs” to only one set  at a time. We can think of this as “declaring” how we are thinking of an element, that is, declaring which set (or which type) an element is being considered as belonging to. (In the jargon, ETCS is a typed theory.) This reflects a general and useful philosophic principle: that elements in isolation are considered inessential, that what counts are the aggregates or contexts in which elements are organized and interrelated. For instance, the numeral ‘2’ in isolation has no meaning; what counts is the context in which we think of it (qua rational number or qua complex number, etc.). Similarly the set of real numbers has no real sense in isolation; what counts is which category we view it in.
at a time. We can think of this as “declaring” how we are thinking of an element, that is, declaring which set (or which type) an element is being considered as belonging to. (In the jargon, ETCS is a typed theory.) This reflects a general and useful philosophic principle: that elements in isolation are considered inessential, that what counts are the aggregates or contexts in which elements are organized and interrelated. For instance, the numeral ‘2’ in isolation has no meaning; what counts is the context in which we think of it (qua rational number or qua complex number, etc.). Similarly the set of real numbers has no real sense in isolation; what counts is which category we view it in.
I believe it is reasonable to grant this principle a foundational status, but: rigorous adherence to this principle completely changes the face of what set theory looks like. If elements “belong” to only one set at a time, how then do we even define such basic concepts as subsets and intersections? These are some of these issues we discussed last time.
There are other significant differences between ZFC and ETCS: stylistically, or in terms of presentation, ZFC is more “top-down” and ETCS is more “bottom-up”. For example, in ZFC, one can pretty much define a subset  by writing down a first-order formula
by writing down a first-order formula 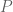 in the language; the comprehension (or separation) axiom scheme is a mighty sledgehammer that takes care of the rest. In the axioms of ETCS, there is no such sledgehammer: the closest thing one has to a comprehension scheme in the ETCS axioms is the power set axiom (a single axiom, not an axiom scheme). However, in the formal development of ETCS, one derives a comprehension scheme as one manually constructs the internal logic, in stages, using the simple tools of adjunctions and universal properties. We started doing some of that in our last post. So: with ZFC it’s more as if you can just hop in the car and go; with ETCS you build the car engine from smaller parts with your bare hands, but in the process you become an expert mechanic, and are not so rigidly attached to a particular make and model (e.g., much of the theory is built just on the axioms of a topos, which allows a lot more semantic leeway than one has with ZF).
in the language; the comprehension (or separation) axiom scheme is a mighty sledgehammer that takes care of the rest. In the axioms of ETCS, there is no such sledgehammer: the closest thing one has to a comprehension scheme in the ETCS axioms is the power set axiom (a single axiom, not an axiom scheme). However, in the formal development of ETCS, one derives a comprehension scheme as one manually constructs the internal logic, in stages, using the simple tools of adjunctions and universal properties. We started doing some of that in our last post. So: with ZFC it’s more as if you can just hop in the car and go; with ETCS you build the car engine from smaller parts with your bare hands, but in the process you become an expert mechanic, and are not so rigidly attached to a particular make and model (e.g., much of the theory is built just on the axioms of a topos, which allows a lot more semantic leeway than one has with ZF).
But, in all fairness, that is perhaps the biggest obstacle to learning ETCS: at the outset, the tools available [mainly, the idea of a universal property] are quite simple but parsimonious, and one has to learn how to build some set-theoretic and logical concepts normally taken as “obvious” from the ground up. (Talk about “foundations”!) On the plus side, by building big logical machines from scratch, one gains a great deal of insight into the inner workings of logic, with a corresponding gain in precision and control and modularity when one would like to use these developments to design, say, automated deduction systems (where there tend to be strong advantages to using type-theoretic frameworks).
Enough philosophy for now; readers may refer to my earlier posts for more. Let’s get to work, shall we? Our last post was about the structure of (and relationships between) posets of subobjects 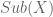 relative to objects
relative to objects  , and now we want to exploit the results there to build some absolute constructions, in particular finite coproducts and coequalizers. In this post we will focus on coproducts.
, and now we want to exploit the results there to build some absolute constructions, in particular finite coproducts and coequalizers. In this post we will focus on coproducts.
Note to the experts: Most textbook treatments of the formal development of topos theory (as for example Mac Lane-Moerdijk) are efficient but highly technical, involving for instance the slice theorem for toposes and, in the construction of colimits, recourse to Beck’s theorem in monad theory applied to the double power-set monad [following the elegant construction of Paré]. The very abstract nature of this style of argumentation (which in the application of Beck’s theorem expresses ideas of fourth-order set theory and higher) is no doubt partly responsible for the somewhat fearsome reputation of topos theory.
In these notes I take a much less efficient but much more elementary approach, based on an arrangement of ideas which I hope can be seen as “natural” from the point of view of naive set theory. I learned of this approach from Myles Tierney, who was my PhD supervisor, and who with Bill Lawvere co-founded elementary topos theory, but I am not aware of any place where the details of this approach have been written up before now. I should also mention that the approach taken here is not as “purist” as many topos theorists might want; for example, here and there I take advantage of the strong extensionality axiom of ETCS to simplify some arguments.
The Empty Set and Two-Valued Logic
We begin with the easy observation that a terminal category, i.e., a category  with just one object and one morphism (the identity), satisfies all the ETCS axioms. Ditto for any category
with just one object and one morphism (the identity), satisfies all the ETCS axioms. Ditto for any category  equivalent to (where every object is terminal). Such boring ETCS categories are called degenerate; obviously our interest is in the structure of nondegenerate ETCS categories.
equivalent to (where every object is terminal). Such boring ETCS categories are called degenerate; obviously our interest is in the structure of nondegenerate ETCS categories.
Let 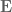 be an ETCS category (see here for the ETCS axioms). Objects of are generally called “sets”, and morphisms are generally called “functions” or “maps”.
be an ETCS category (see here for the ETCS axioms). Objects of are generally called “sets”, and morphisms are generally called “functions” or “maps”.
Proposition 0: If an ETCS category is a preorder, then is degenerate.
Proof: Recall that a preorder is a category in which there is at most one morphism 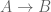 for any two objects . Every morphism in a preorder is vacuously monic. If there is a nonterminal set , then the monic
for any two objects . Every morphism in a preorder is vacuously monic. If there is a nonterminal set , then the monic  to any terminal set defines a subset
to any terminal set defines a subset 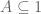 distinct from the subset defined by
distinct from the subset defined by 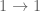 , thus giving (in an ETCS category) distinct classifying maps
, thus giving (in an ETCS category) distinct classifying maps 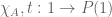 , contradicting the preorder assumption. Therefore all objects are terminal.
, contradicting the preorder assumption. Therefore all objects are terminal. 
Assume from now on that is a nondegenerate ETCS category.
Proposition 1: There are at least two truth values, i.e., two elements 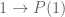 , in .
, in .
Proof: By proposition 0, there exist sets 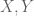 and two distinct functions
and two distinct functions  . By the axiom of strong extensionality, there exists
. By the axiom of strong extensionality, there exists 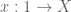 such that
such that 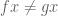 . The equalizer
. The equalizer 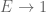 of the pair
of the pair 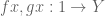 is then a proper subset of
is then a proper subset of  , and therefore there are at least two distinct elements
, and therefore there are at least two distinct elements  .
.
Proposition 2: There are at most two truth values ; equivalently, there are at most two subsets of .
Proof: If 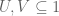 are distinct subsets of , then either
are distinct subsets of , then either 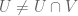 or
or 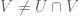 , say the former. Then
, say the former. Then  and
and  are distinct subsets, with distinct classifying maps
are distinct subsets, with distinct classifying maps 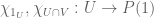 . By strong extensionality, there exists
. By strong extensionality, there exists  distinguishing these classifying maps. Because is terminal, we then infer
distinguishing these classifying maps. Because is terminal, we then infer  and
and  , so
, so 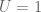 as subsets of , and in that case only
as subsets of , and in that case only  can be a proper subset of .
can be a proper subset of .
By propositions 1 and 2, there is a unique proper subset of the terminal object . Let 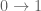 denote this subset. Its domain may be called an “empty set”; by the preceding proposition, it has no proper subsets. The classifying map
denote this subset. Its domain may be called an “empty set”; by the preceding proposition, it has no proper subsets. The classifying map  of
of  is the truth value we call “false”.
is the truth value we call “false”.
Proposition 3: 0 is an initial object, i.e., for any there exists a unique function 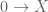 .
.
Proof: Uniqueness: if  are maps, then their equalizer
are maps, then their equalizer 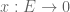 , which is monic, must be an isomorphism since 0 has no proper subsets. Therefore
, which is monic, must be an isomorphism since 0 has no proper subsets. Therefore 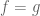 . Existence: there are monos
. Existence: there are monos


where 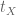 is “global truth” (classifying the subset
is “global truth” (classifying the subset  ) on and
) on and  is the “singleton mapping
is the “singleton mapping 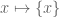 ” on , defined as the classifying map of the diagonal map
” on , defined as the classifying map of the diagonal map  (last time we saw is monic). Take their pullback. The component of the pullback parallel to is a mono
(last time we saw is monic). Take their pullback. The component of the pullback parallel to is a mono 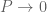 which again is an isomorphism, whence we get a map
which again is an isomorphism, whence we get a map 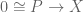 using the other component of the pullback.
using the other component of the pullback.
Remark: For the “purists”, an alternative construction of the initial set 0 that avoids use of the strong extensionality axiom is to define the subset to be “the intersection all subsets of “. Formally, one takes the extension ![\left[\phi\right] \subseteq 1](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cphi%5Cright%5D+%5Csubseteq+1&bg=ffffff&fg=545454&s=0&c=20201002) of the map
of the map

where the first arrow represents the class of all subsets of  , and the second is the internal intersection operator defined at the end of our last post. Using formal properties of intersection developed later, this intersection has no proper subsets, and then the proof of proposition 3 carries over verbatim.
, and the second is the internal intersection operator defined at the end of our last post. Using formal properties of intersection developed later, this intersection has no proper subsets, and then the proof of proposition 3 carries over verbatim.
Corollary 1: For any , the set  is initial.
is initial.
Proof: By cartesian closure, maps 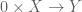 are in bijection with maps of the form
are in bijection with maps of the form  , and there is exactly one of these since 0 is initial.
, and there is exactly one of these since 0 is initial.
Corollary 2: If there exists  , then is initial.
, then is initial.
Proof: The composite of  followed by
followed by  is
is  , and
, and  followed by is also an identity since is initial by corollary 1. Hence is isomorphic to an initial object .
followed by is also an identity since is initial by corollary 1. Hence is isomorphic to an initial object .
By corollary 2, for any object  the arrow
the arrow  is vacuously monic, hence defines a subset.
is vacuously monic, hence defines a subset.
Proposition 4: If  , then there exists an element .
, then there exists an element .
Proof: Under the assumption, has at least two distinct subsets: 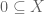 and
and 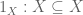 . By strong extensionality, their classifying maps
. By strong extensionality, their classifying maps  are distinguished by some element .
are distinguished by some element .
External Unions and Internal Joins
One of the major goals in this post is to construct finite coproducts in an ETCS category. As in ordinary set theory, we will construct these as disjoint unions. This means we need to discuss unions first; as should be expected by now, in ETCS unions are considered locally, i.e., we take unions of subsets of a given set. So, let 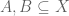 be subsets.
be subsets.
To define the union  , the idea is to take the intersection of all subsets containing and
, the idea is to take the intersection of all subsets containing and  . That is, we apply the internal intersection operator (constructed last time),
. That is, we apply the internal intersection operator (constructed last time),

to the element  that represents the set of all subsets of containing and ; the resulting element
that represents the set of all subsets of containing and ; the resulting element  represents
represents  . The element corresponds to the intersection of two subsets
. The element corresponds to the intersection of two subsets

Remark: Remember that in ETCS we are using generalized elements:  really means a function
really means a function 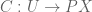 over some domain
over some domain  , which in turn classifies a subset
, which in turn classifies a subset ![\left[C\right] \subseteq U \times X](https://s0.wp.com/latex.php?latex=%5Cleft%5BC%5Cright%5D+%5Csubseteq+U+%5Ctimes+X&bg=ffffff&fg=545454&s=0&c=20201002) . On the other hand, the here is a subset
. On the other hand, the here is a subset 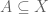 . How then do we interpret the condition “
. How then do we interpret the condition “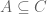 “? We first pull back
“? We first pull back  over to the domain ; that is, we form the composite
over to the domain ; that is, we form the composite 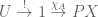 , and consider the condition that this is bounded above by . (We will write
, and consider the condition that this is bounded above by . (We will write  , thinking of the left side as constant over .) Externally, in terms of subsets, this corresponds to the condition
, thinking of the left side as constant over .) Externally, in terms of subsets, this corresponds to the condition ![U \times A \subseteq \left[C\right]](https://s0.wp.com/latex.php?latex=U+%5Ctimes+A+%5Csubseteq+%5Cleft%5BC%5Cright%5D&bg=ffffff&fg=545454&s=0&c=20201002) .
.
We need to construct the subsets 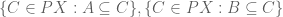 . In ZFC, we could construct those subsets by applying the comprehension axiom scheme, but the axioms of ETCS have no such blanket axiom scheme. (In fact, as we said earlier, much of the work on “internalizing logic” goes to show that in ETCS, we instead derive a comprehension scheme!) However, one way of defining subsets in ETCS is by taking loci of equations; here, we express the condition , more pedantically
. In ZFC, we could construct those subsets by applying the comprehension axiom scheme, but the axioms of ETCS have no such blanket axiom scheme. (In fact, as we said earlier, much of the work on “internalizing logic” goes to show that in ETCS, we instead derive a comprehension scheme!) However, one way of defining subsets in ETCS is by taking loci of equations; here, we express the condition , more pedantically ![A \subseteq \left[C\right]](https://s0.wp.com/latex.php?latex=A+%5Csubseteq+%5Cleft%5BC%5Cright%5D&bg=ffffff&fg=545454&s=0&c=20201002) or , as the equation
or , as the equation

where the right side is the predicate “true over “.
Thus we construct the subset 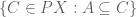 of
of  via the pullback:
via the pullback:
{C: A ≤ C} -------> 1
| |
| | t_X
V chi_A => - V
PX -----------> PX
Let me take a moment to examine what this diagram means exactly. Last time we constructed an internal implication operator

and now, in the pullback diagram above, what we are implicitly doing is lifting this to an operator

The easy and cheap way of doing this is to remember the isomorphism  we used last time to uncover the cartesian closed structure, and apply this to
we used last time to uncover the cartesian closed structure, and apply this to

to define . This map classifies a certain subset of 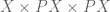 , which I’ll just write down (leaving it as an exercise which involves just chasing the relevant definitions):
, which I’ll just write down (leaving it as an exercise which involves just chasing the relevant definitions):
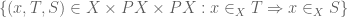
Remark: Similarly we can define a meet operator 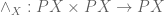 by exponentiating the internal meet
by exponentiating the internal meet 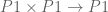 . It is important to know that the general Heyting algebra identities which we established last time for lift to the corresponding identities for the operators
. It is important to know that the general Heyting algebra identities which we established last time for lift to the corresponding identities for the operators  on . Ultimately this rests on the fact that the functor
on . Ultimately this rests on the fact that the functor  , being a right adjoint, preserves products, and therefore preserves any algebraic identity which can be expressed as a commutative diagram of operations between such products.
, being a right adjoint, preserves products, and therefore preserves any algebraic identity which can be expressed as a commutative diagram of operations between such products.
Hence, for the fixed subset (classified by ), the operator

classifies the subset
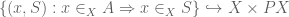
Finally, in the pullback diagram above, we are pulling back the operator 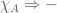 against . But, from last time, that was exactly the method we used to construct universal quantification. That is, given a subset
against . But, from last time, that was exactly the method we used to construct universal quantification. That is, given a subset
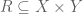
we defined  to be the pullback of
to be the pullback of  along
along  . Putting all this together, the pullback diagram above expresses the definition
. Putting all this together, the pullback diagram above expresses the definition

that one would expect “naively”.
Now that all the relevant constructions are in place, we show that is the join of and in the poset . There is nothing intrinsically difficult about this, but as we are still in the midst of constructing the internal logic, we will have to hunker down and prove some logic things normally taken for granted or zipped through without much thought. For example, the internal intersection operator was defined with the help of internal universal quantification, and we will need to establish some formal properties of that.
Here is a useful general principle for doing internal logic calculations. Let be the classifying map of a subset , and let 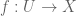 be a function. Then the composite
be a function. Then the composite 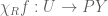 classifies the subset
classifies the subset

so that one has the general identity  . In passing back and forth between the external and internal viewpoints, the general principle is to try to render “complicated” functions
. In passing back and forth between the external and internal viewpoints, the general principle is to try to render “complicated” functions 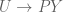 into a form
into a form  which one can more easily recognize. For lack of a better term, I’ll call this the “pullback principle”.
which one can more easily recognize. For lack of a better term, I’ll call this the “pullback principle”.
Lemma 1: Given a relation  and a constant
and a constant 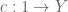 , there is an inclusion
, there is an inclusion

as subsets of . (In traditional logical syntax, this says that for any element ,
 implies
implies 
as predicates over elements 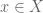 . This is the type of thing that ordinarily “goes without saying”, but which we actually have to prove here!)
. This is the type of thing that ordinarily “goes without saying”, but which we actually have to prove here!)
Proof: As we recalled above, was defined to be  , the pullback of global truth
, the pullback of global truth  along the classifying map . Hold that thought.
along the classifying map . Hold that thought.
Let

be the map which classifies the subset  . Equivalently, this is the map
. Equivalently, this is the map
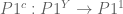
under the canonical isomorphisms  ,
, 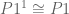 . Intuitively, this maps
. Intuitively, this maps  , i.e., plugs an element
, i.e., plugs an element  into an element
into an element 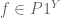 .
.
Using the adjunction  of cartesian closure, the composite
of cartesian closure, the composite
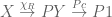
transforms to the composite

so by the pullback principle,  classifies
classifies  .
.
Equivalently,

Also, as subsets of  , we have the inclusion
, we have the inclusion
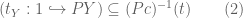
[this just says that  belongs to the subset classified by
belongs to the subset classified by 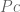 , or equivalently that is in the subset
, or equivalently that is in the subset  ]. Applying the pullback operation
]. Applying the pullback operation 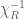 to (2), and comparing to (1), lemma 1 follows.
to (2), and comparing to (1), lemma 1 follows.
Lemma 2: If  as subsets of
as subsets of 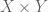 , then
, then 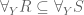 .
.
Proof: From the last post, we have an adjunction:
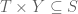 if and only if
if and only if 
for any subset of  . So it suffices to show
. So it suffices to show  . But
. But

where the first inclusion follows from  .
.
Next, recall from the last post that the internal intersection of  was defined by interpreting the following formula on the right:
was defined by interpreting the following formula on the right:
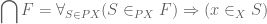
Lemma 3: If  , then
, then 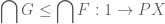 .
.
Proof: classifies the subset 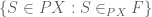 , i.e.,
, i.e.,  is identified with the predicate
is identified with the predicate 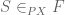 in the argument
in the argument  , so by hypothesis
, so by hypothesis 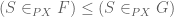 as predicates on . Internal implication
as predicates on . Internal implication  is contravariant in the argument
is contravariant in the argument  [see the following remark], so
[see the following remark], so
![\left[(S \in G) \Rightarrow (x \in S)\right] \leq \left[(S \in F) \Rightarrow (x \in S)\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%28S+%5Cin+G%29+%5CRightarrow+%28x+%5Cin+S%29%5Cright%5D+%5Cleq+%5Cleft%5B%28S+%5Cin+F%29+%5CRightarrow+%28x+%5Cin+S%29%5Cright%5D&bg=ffffff&fg=545454&s=0&c=20201002)
Now apply lemma 2 to complete the proof.
Remark: The contravariance of 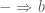 , that is, the fact that
, that is, the fact that
 implies
implies 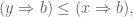
is a routine exercise using the adjunction [discussed last time]
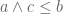 if and only if
if and only if 
Indeed, we have

where the first inequality follows from the hypothesis , and the second follows from  . By the adjunction, the inequality (*) implies
. By the adjunction, the inequality (*) implies 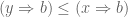 .
.
Theorem 1: For subsets of , the subset is an upper bound of and , i.e., 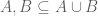 .
.
Proof: It suffices to prove that  , since then we need only apply lemma 3 to the trivially true inclusion
, since then we need only apply lemma 3 to the trivially true inclusion
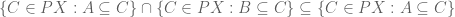
to infer  , and similarly
, and similarly  . (Actually, we need only show
. (Actually, we need only show 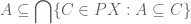 . We’ll do that first, and then show full equality.)
. We’ll do that first, and then show full equality.)
The condition we want,

is, by the adjunction  , equivalent to
, equivalent to

which, by a  –
–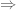 adjunction, is equivalent to
adjunction, is equivalent to

as subsets of 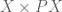 . So we just have to prove (1). At this point we recall, from our earlier analysis, that
. So we just have to prove (1). At this point we recall, from our earlier analysis, that

Using the adjunction  , as in the proof of lemma 2, we have
, as in the proof of lemma 2, we have
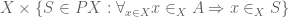
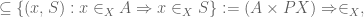
which shows that the left side of (1) is contained in

where the last inclusion uses another – adjunction. Thus we have established (1) and therefore also the inclusion
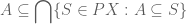
Now we prove the opposite inclusion
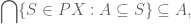
that is to say
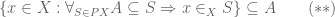
Here we just use lemma 1, applied to the particular element : we see that the left side of (**) is contained in
![\{x \in X: A \subseteq \left[\chi_A\right] \Rightarrow x \in_X A\}](https://s0.wp.com/latex.php?latex=%5C%7Bx+%5Cin+X%3A+A+%5Csubseteq+%5Cleft%5B%5Cchi_A%5Cright%5D+%5CRightarrow+x+%5Cin_X+A%5C%7D&bg=ffffff&fg=545454&s=0&c=20201002)
which collapses to  , since
, since ![A = \left[\chi_A\right]](https://s0.wp.com/latex.php?latex=A+%3D+%5Cleft%5B%5Cchi_A%5Cright%5D&bg=ffffff&fg=545454&s=0&c=20201002) . This completes the proof.
. This completes the proof.
Theorem 2: is the least upper bound of , i.e., if  is a subset containing both and
is a subset containing both and  , then
, then  .
.
Proof: We are required to show that

Again, we just apply lemma 1 to the particular element 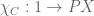 : the left-hand side of the claimed inclusion is contained in
: the left-hand side of the claimed inclusion is contained in

but since  is true by hypothesis (is globally true as a predicate on the implicit variable ), this last subset collapses to
is true by hypothesis (is globally true as a predicate on the implicit variable ), this last subset collapses to

which completes the proof.
Theorems 1 and 2 show that for any set , the external poset admits joins. One may go on to show (just on the basis of the topos axioms) that as in the case of meets, the global external operation of taking joins is natural in , so that by the Yoneda principle, it is classified by an internal join operation

namely, the map which classifies the union of the subsets
![\displaystyle \left[\pi_1\right] = P1 \times 1 \stackrel{1 \times t}{\hookrightarrow} P1 \times P1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B%5Cpi_1%5Cright%5D+%3D+P1+%5Ctimes+1+%5Cstackrel%7B1+%5Ctimes+t%7D%7B%5Chookrightarrow%7D+P1+%5Ctimes+P1&bg=ffffff&fg=545454&s=0&c=20201002)
![\displaystyle \left[\pi_2\right] = 1 \times P1 \stackrel{t \times 1}{\hookrightarrow} P1 \times P1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B%5Cpi_2%5Cright%5D+%3D+1+%5Ctimes+P1+%5Cstackrel%7Bt+%5Ctimes+1%7D%7B%5Chookrightarrow%7D+P1+%5Ctimes+P1&bg=ffffff&fg=545454&s=0&c=20201002)
and this operation satisfies all the expected identities. In short, carries an internal Heyting algebra structure, as does for any set .
We will come back to this point later, when we show (as a consequence of strong extensionality) that is actually an internal Boolean algebra.
Construction of Coproducts
Next, we construct coproducts just as we do in ordinary set theory: as disjoint unions. Letting be sets (objects in an ETCS category), a disjoint union of and is a pair of monos

whose intersection is empty, and whose union or join in 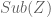 is all of
is all of 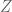 . We will show that disjoint unions exist and are essentially unique, and that they satisfy the universal property for coproducts. We will use the notation
. We will show that disjoint unions exist and are essentially unique, and that they satisfy the universal property for coproducts. We will use the notation 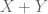 for a disjoint union.
for a disjoint union.
Theorem 3: A disjoint union of and exists.
Proof: It’s enough to embed disjointly into some set , since the union of the two monos in 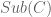 would then be the requisite . The idea now is that if a disjoint union or coproduct
would then be the requisite . The idea now is that if a disjoint union or coproduct 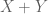 exists, then there’s a canonical isomorphism
exists, then there’s a canonical isomorphism  . Since the singleton map
. Since the singleton map
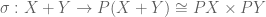
is monic, one thus expects to be able to embed and disjointly into  . Since we can easily work out how all this goes in ordinary naive set theory, we just write out the formulas and hope it works out in ETCS.
. Since we can easily work out how all this goes in ordinary naive set theory, we just write out the formulas and hope it works out in ETCS.
In detail, define  to be
to be
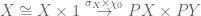
where 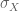 is the singleton mapping and
is the singleton mapping and  classifies
classifies  ; similarly, define
; similarly, define  to be
to be

Clearly  and
and  are monic, so to show disjointness we just have to show that their pullback is empty. But their pullback is isomorphic to the cartesian product of the pullbacks of the diagrams
are monic, so to show disjointness we just have to show that their pullback is empty. But their pullback is isomorphic to the cartesian product of the pullbacks of the diagrams

so it would be enough to show that each (or just one) of these two pullbacks is empty, let’s say the first.
Suppose given a map  which makes the square
which makes the square
A -------> 1
| |
h | | chi_0
V sigma_X V
X -------> PX
commute. Using the pullback principle, the map  classifies
classifies

which is just the empty subset. This must be the same subset as classified by  (where
(where  is the diagonal), which by the pullback principle is
is the diagonal), which by the pullback principle is
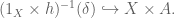
An elementary calculation shows this to be the equalizer of the pair of maps
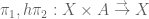
So this equalizer  is empty. But notice that
is empty. But notice that  equalizes this pair of maps. Therefore we have a map
equalizes this pair of maps. Therefore we have a map 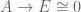 . By corollary 2 above, we infer
. By corollary 2 above, we infer  . This applies to the case where is the pullback, so the pullback is empty, as was to be shown.
. This applies to the case where is the pullback, so the pullback is empty, as was to be shown.
Theorem 4: Any two disjoint unions of are canonically isomorphic.
Proof: Suppose 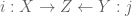 is a disjoint union. Define a map
is a disjoint union. Define a map

where  classifies the subset
classifies the subset 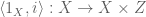 , and
, and  classifies the subset
classifies the subset  . Applying the pullback principle, the composite
. Applying the pullback principle, the composite 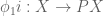 classifies
classifies

which is easily seen to be the diagonal on . Hence  . On the other hand,
. On the other hand,  classifies the subset
classifies the subset
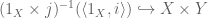
which is empty because  and
and 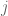 are disjoint embeddings, so
are disjoint embeddings, so  . Similar calculations yield
. Similar calculations yield

Putting all this together, we conclude that  and
and  , where and were defined in the proof of theorem 3.
, where and were defined in the proof of theorem 3.
Next, we show that 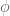 is monic. If not, then by strong extensionality, there exist distinct elements
is monic. If not, then by strong extensionality, there exist distinct elements  for which
for which 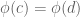 ; therefore,
; therefore,  and
and 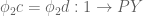 . By the pullback principle, these equations say (respectively)
. By the pullback principle, these equations say (respectively)

If  , then both factor through the mono
, then both factor through the mono  . However, since
. However, since  is monic, this would imply that
is monic, this would imply that 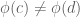 , contradiction. Therefore
, contradiction. Therefore  . By similar reasoning,
. By similar reasoning, 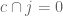 . Therefore
. Therefore

where  is the negation operator. But then
is the negation operator. But then 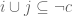 . And since
. And since 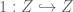 is the union
is the union  by assumption,
by assumption,  must be the top element
must be the top element  , whence
, whence 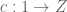 is the bottom element 0. This contradicts the assumption that the topos is nondegenerate. Thus we have shown that must be monic.
is the bottom element 0. This contradicts the assumption that the topos is nondegenerate. Thus we have shown that must be monic.
The argument above shows that 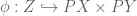 is an upper bound of and in
is an upper bound of and in  . It follows that the join constructed in theorem 3 is contained in
. It follows that the join constructed in theorem 3 is contained in 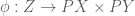 , and hence can be regarded as the join of and in . But is their join in by assumption of being a disjoint union, so the containment
, and hence can be regarded as the join of and in . But is their join in by assumption of being a disjoint union, so the containment  must be an equality. The proof is now complete.
must be an equality. The proof is now complete.
Theorem 5: The inclusions  ,
,  exhibit as the coproduct of and .
exhibit as the coproduct of and .
Proof: Let  ,
, 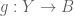 be given functions. Then we have monos
be given functions. Then we have monos

Now the operation 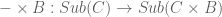 certainly preserves finite meets, and also preserves finite joins because it is left adjoint to
certainly preserves finite meets, and also preserves finite joins because it is left adjoint to  . Therefore this operation preserves disjoint unions; we infer that the monos
. Therefore this operation preserves disjoint unions; we infer that the monos

exhibit  as a disjoint union of
as a disjoint union of 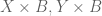 . Composing the monos of (1) and (2), we have disjoint embeddings of and in . Using theorem 4, is isomorphic to the join of these embeddings; this means we have an inclusion
. Composing the monos of (1) and (2), we have disjoint embeddings of and in . Using theorem 4, is isomorphic to the join of these embeddings; this means we have an inclusion

whose restriction to yields  and whose restriction to yields
and whose restriction to yields 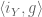 . Hence
. Hence 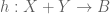 extends
extends  and
and 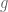 . It is the unique extension, for if there were two extensions
. It is the unique extension, for if there were two extensions 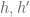 , then the equalizer of
, then the equalizer of  and
and 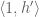 would be an upper bound of in
would be an upper bound of in  , contradicting the fact that is the least upper bound. This completes the proof.
, contradicting the fact that is the least upper bound. This completes the proof.
I think that’s enough for one day. I will continue to explore the categorical structure and logic of ETCS next time.




{kind=link}
7 comments
Comments feed for this article
December 15, 2008 at 2:11 pm
Can Category Theory Serve as the Foundation of Mathematics? « Combinatorics and more
[…] and Vishal Blog) a series of posts ( I, II, III) on category theory, and additional posts (I,II, III) on category theory and axiomatic set theory. See also the […]
December 16, 2008 at 6:30 am
Tom Leinster
Todd, these posts on ETCS are wonderful. I’ve been fantasizing for a while about teaching a categorical set theory course to undergraduates. If it ends up happening, your posts will be a really valuable resource. And even if not, I’m enjoying and learning from them now.
December 16, 2008 at 5:30 pm
Todd Trimble
Thanks so much, Tom! Coming from you, it means a lot.
And let me please encourage you to roll up your sleeves and do some editing of these posts over at nLab, if you have the time and inclination. These somewhat dense posts would probably benefit from a graceful and gentle expositional touch from say you or John Baez.
And by all means, teach that course! I’d be interested to read any notes you write up.
December 17, 2008 at 9:30 pm
Todd Trimble
The principle of context dependence described in the preamble of this post (see the fifth paragraph) is of course nothing new. I happened to run across it again in some philosophical work on categories here (see point 3 on page 7).
December 18, 2008 at 1:08 am
Sridhar Ramesh
You note “In the axioms of ETCS, there is no such sledgehammer: the closest thing one has to a comprehension scheme in the ETCS axioms is the power set axiom (a single axiom, not an axiom scheme). However, in the formal development of ETCS, one derives a comprehension scheme as one manually constructs the internal logic, in stages, using the simple tools of adjunctions and universal properties.” as one of the examples where arduous construction from a very limited set of primitives can scare people off from category-theoretic foundations. But, of course, one could simply adopt a suitably direct formulation of the logical connectives, comprehension scheme, colimits, exponentials, etc., as part of one’s axiomatization of a topos. Then, the realization that such an axiomatization is redundant and could be pared down to your more parsimonious version would be a nice technical curiosity (and helpful for readily appreciating various mathematical “universes” of preexisting interest as actually satisfying the axioms), but not a hurdle which one would have to learn to clear before being able to understand how to carry out mathematical arguments in topos-logical reasoning. To fail to stress this is perhaps to help paint the false picture of reasoning within the typed set theory of a topos as further removed from the actual practice of mathematicians than it really is. [Or, at the very least, one should point out that similar problems of “Some assembly required” manifest when taking a correspondingly strict approach to set theoretical foundations; e.g., having to define ordered pairs in some messy way such as Kuratowski’s, constructing natural numbers as von Neumann ordinals, etc.]
December 18, 2008 at 1:27 am
Sridhar Ramesh
That’s not meant to be a slam on this series of posts at all, which I think are great; these posts surely have a largely different motivation than the one for which I was saying a shift in emphasis or approach would be helpful. But I just wanted to point out one way in which anxiety and misunderstanding is liable to arise when one attempts to demonstrate the utility of category-theoretic foundations to those accustomed only to thinking otherwise.
December 18, 2008 at 3:23 am
Todd Trimble
Thanks, Sridhar. You raise a valid point. The following was what I was writing before I saw your second comment, which I appreciate.
I think the original writings of Lawvere on ETCS come a little closer to what you’re suggesting: his axioms on a category C of sets included existence of finite limits, colimits, exponentials, had 2 = 1 + 1 as subobject classifier, and so on. This was well before elementary topos theory was on the scene, and well before it was understood to what extent Lawvere’s axioms were redundant. Other early work by Lawvere on hyperdoctrines clarified the categorical perspective on first-order logic [and generalizations thereof], in which one has a fibration E –> C in which the fibers admit some form of generalized propositional logic, and with adjoints on both sides to pullback operations so that one can represent universal and existential quantification, preferably satisfying so-called Beck-Chevalley conditions.
So, it would indeed be possible just to write down a huge list of axioms in which meld these perspectives: a base category C with all that nice structure, and hyperdoctrine axioms on the fibration Sub(C) –> C [where the fiber over an object x of C is Sub(x), the poset of subobjects of x] so that one could straightaway begin interpreting first-order logic. But, that’s a pretty big list of axioms, and it would probably strike the uninitiated as cumbersome, and difficult to motivate when placed side by side with ZFC.
So one has to make aesthetic decisions about presentational matters: where to begin and how much to assume axiomatically. I think if my main interest in these posts were just to show that it’s merely possible to found set theory on categorical terms, then it might make better sense to start with a more axiom-heavy presentation [although I fear that would provide ammunition for certain hide-bound set theorists to sneer at the whole project].
So I may as well come out and say that one of my real motivations is to develop an account of topos theory etc. which starts off as most accounts do with parsimonious axioms, but is alternative to the mainline textbook accounts in that in essence it tries to hew a little closer to common-sense set-theoretic reasoning, or is less dependent on technical categorical background, while at the same time developing categorical insights along the way. This still makes certain demands on the reader [people who read my stuff know by now that I pull no punches!], but some of the feedback I’ve been getting encourages to push on in this direction, and I think I’ll summarize later how the ultimate goal (of showing how naive set-theoretic reasoning can be naturally modeled categorically) has been achieved.
I encourage you and other people who grok what’s going on to try their hand at different modes of presentation! It’s worth the effort, I believe.