
You are currently browsing the tag archive for the ‘Szego’ tag.
Part 2:
After having understood the inclusion-exclusion principle by working out a few cases and examples in my earlier post, we are now ready to prove the general version of the principle.
As with many things in mathematics, there is a “normal” way of doing proofs and there is the “Polya/Szego” way of doing proofs. (Ok, ok, I admit it’s just a bias I have.) I will stick to the latter. Ok, let’s state the principle first and follow it up with its proof in a step-by-step fashion.
Inclusion-Exclusion Principle: Let there be a set of 
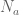


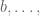



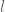





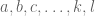



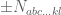
— Notation —
Let 
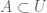



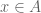
and 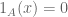

For example, suppose 
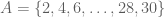

Note: 


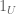
—
Lemma 1: 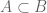

Proof: We first prove the “only if”part. So, suppose 
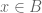


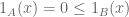
We now prove the “if” part. So, suppose
Note: If 
Lemma 2:



for all 
Proof: The proof for each case is elementary.
Lemma 3: Suppose 
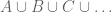


Proof: Note the above is an extension of the third part of lemma 
— Proof of the inclusion-exclusion principle —
Now, suppose 





Expand the last expression to get


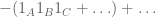

Now, sum over all the elements of
[Update: Thanks to Andreas for pointing out that I may have been a little sloppy in stating the maximum modulus principle! The version below is an updated and correct one. Also, Andreas pointed out an excellent post on “amplification, arbitrage and the tensor power trick” (by Terry Tao) in which the “tricks” discussed are indeed very useful and far more powerful generalizations of the “method” of E. Landau discussed in this post. The Landau method mentioned here, it seems, is just one of the many examples of the “tensor power trick”.]
The maximum modulus principle states that if 

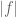
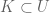



Problems and Theorems in Analysis II, by Polya and Szego, provides a short proof of the “inequality part” of the principle. The proof by E. Landau employs Cauchy’s integral formula, and the technique is very interesting and useful indeed. The proof is as follows.
From Cauchy’s integral formula, we have

for every 

Now, suppose 

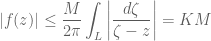
where the constant 

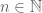


By allowing 

Polya/Szego mention that the proof shows that a rough estimate may sometimes be transformed into a sharper estimate by making appropriate use of the generality for which the original estimate is valid.
I will follow this up with, maybe, a couple of problems/solutions to demonstrate the effectiveness of this useful technique.
The Harvard College Mathematics Review (HCMR) published its inaugural issue in April 2007, and the second issue was out almost a fortnight ago. Clearly, the level of exposition contained in the articles is extremely high, and it is a pleasure reading all the articles even though a lot of it may not make a lot of sense to a lot of people. I would recommend anyone to visit their website and browse all their issues. For problem-solvers, the problem section in each issue is a delight!
Anyway, the first issue’s problem section contained a somewhat hard inequality problem (proposed by Shrenik Shah), which I was able to solve and for which my solution was acknowledged in the problem section of the second issue. The HCMR carried Greg Price’s solution to that particular problem, and I must say his solution is somewhat more “natural” and “intuitive” than the one I gave.
Well, I want to present my solution here but in a more detailed fashion. In particular, I want to develop the familiar 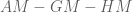
Problem: For all distinct positive reals
, show that
.
First, let us discuss some facts.
1. 
![\displaystyle (x_1 + x_2 + \ldots + x_n)/n \geq \sqrt[n]{x_1x_2\cdots x_n} \geq \frac{n}{1/x_1 + 1/x_2 + \ldots + 1/x_n}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%28x_1+%2B+x_2+%2B+%5Cldots+%2B+x_n%29%2Fn+%5Cgeq+%5Csqrt%5Bn%5D%7Bx_1x_2%5Ccdots+x_n%7D+%5Cgeq+%5Cfrac%7Bn%7D%7B1%2Fx_1+%2B+1%2Fx_2+%2B+%5Cldots+%2B+1%2Fx_n%7D&bg=ffffff&fg=545454&s=0&c=20201002)
with equality if and only if 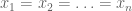
Proof: For a hint on proving the above using mathematical induction, read this. However, we will make use of Jensen’s inequality to prove the above result. We won’t prove Jensen’s inequality here, though it too can be proved using induction.
Jensen’s inequality: Let 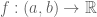


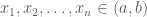
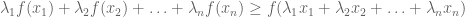
with equality if and only if
Now, in order to prove (1), consider the function 

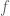

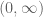
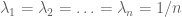

![\displaystyle \Rightarrow \frac{x_1 + x_2 + \ldots + x_n}{n} \geq \sqrt[n]{x_1x_2\cdots x_n} \quad \ldots](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CRightarrow+%5Cfrac%7Bx_1+%2B+x_2+%2B+%5Cldots+%2B+x_n%7D%7Bn%7D+%5Cgeq+%5Csqrt%5Bn%5D%7Bx_1x_2%5Ccdots+x_n%7D+%5Cquad+%5Cldots+&bg=ffffff&fg=545454&s=0&c=20201002)

This proves the first part of the inequality in (1). Now, replace each 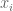

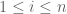
We can generalize this further. Indeed, for any positive reals 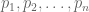

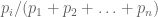
2. Generalized Cauchy Inequality (non-integral version) : For any positive reals
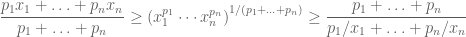
Now, the remarkable thing is we can generalize the above inequality even further to obtain the following integral version of the inequality.
3. Generalized Cauchy Inequality (integral version) : Let 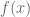

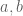

where 
Okay, now we are finally ready to solve our original problem. First, without any loss of generality, we can assume 
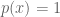

Thus, we have 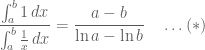
Also, 
And, 
Combining 




Recent Comments